

How context bloat silently inflates token spend, degrades output quality, and what you can actually do about it.
The Day My AI Started Getting Dumber
Three months ago, I was six weeks deep into a project using an AI coding assistant — Cursor as my primary development partner.
The early days were fast. Architecture decisions, database schema, API design — the AI nailed it. Responses were sharp, context-aware, and rarely needed more than one retry.
Then something shifted.
By week four, the same assistant that had helped me design the system was now hallucinating function signatures from two weeks earlier, suggesting fixes for bugs I had already resolved, and occasionally ignoring the actual question entirely to riff on unrelated parts of the codebase.
I spent a day blaming the model. Then another blaming the IDE. Then I looked at the conversation.
It was 190,000 tokens long.
I started a fresh chat, pasted in a two-paragraph summary of the current problem, and got a better answer in under 10 seconds.
The model hadn't changed. The environment had become unworkable.
That's when I understood: AI quality is not just a model problem. It's an architecture problem.
What Token Inflation Actually Looks Like
Token inflation is what happens when your AI architecture generates tokens it doesn't need.
Not because the model charges more per token. Because the system sends more tokens per task — most of which carry no informational value for the current problem.
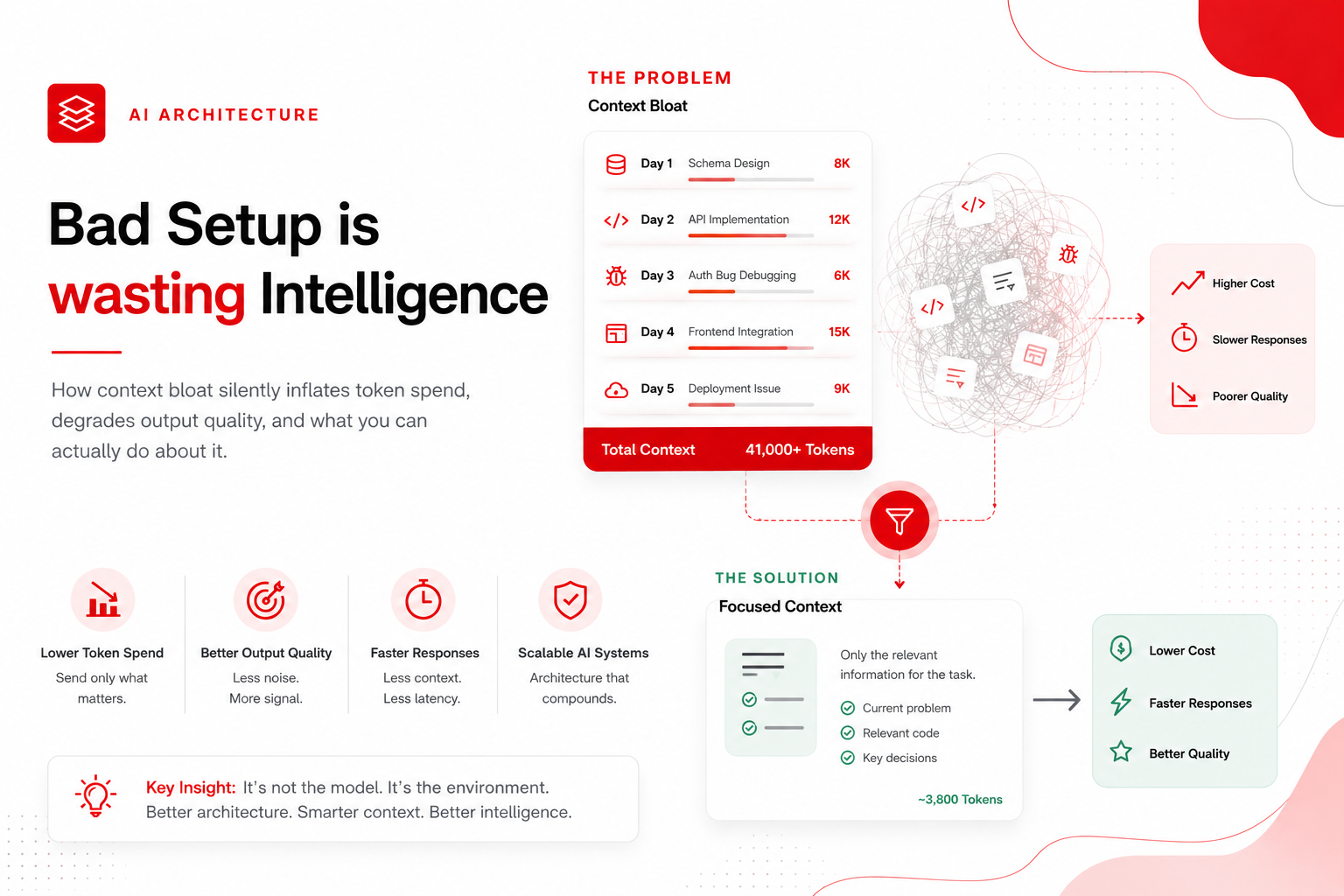
Here's a concrete example. In a week-long feature development session, a single conversation might accumulate:
- Day 1: Database schema design (~8,000 tokens of back-and-forth)
- Day 2: API route implementation (~12,000 tokens)
- Day 3: A bug in the auth middleware (~6,000 tokens of debugging)
- Day 4: Frontend integration (~15,000 tokens)
- Day 5: A completely unrelated deployment issue (~9,000 tokens)
By day 5, every single request carries 41,000 tokens of prior context — schema decisions, auth bug traces, frontend component code — before the model even starts thinking about the deployment question.
In my own workflow, I measured this directly. A deployment debugging question asked mid-conversation (with full history loaded) consumed approximately 52,000 tokens per iteration. The same question in a fresh chat with a targeted two-paragraph context summary: 3,800 tokens. Same answer quality. 93% token reduction.
That's not a model efficiency problem. That's an architecture problem.
Context Debt: The Technical Debt Nobody Is Tracking
Software engineers have internalized technical debt. They track it, schedule it, argue about it in sprint planning. But almost no engineering team tracks context debt — and it has the same compounding properties.
Context debt accumulates when an AI workflow carries:
- Irrelevant information: Previous features, old bug traces, superseded requirements
- Outdated information: Architectural decisions that were reversed, dependencies that changed
- Duplicate information: The same codebase summary generated by three different agents
- Poorly structured information: Raw chat history when a structured summary would serve better
Like technical debt, context debt compounds. Every new session adds weight. And unlike technical debt, it doesn't show up in your backlog — it shows up as degraded AI output that you attribute to the model.
The tell: if a fresh chat on the same problem gives meaningfully better results than a context-heavy one, you have context debt. It's not the model underperforming. It's the environment forcing the model to do unnecessary work before it can start reasoning about your actual question.
Why "More Context" Is Often the Wrong Instinct
The intuitive response to poor AI output is to add more context.
More files. More instructions. More examples. More retrieval. More agents reviewing each other's work.
This is sometimes right. Often it's exactly wrong.
Here's why: language models don't read context sequentially and prioritize what matters. They process everything in the window simultaneously. Relevant and irrelevant information compete for the model's attention. When the window is dense with noise, signal degrades.
This is why RAG (retrieval-augmented generation) or other similar architectures often outperform "throw everything in" approaches even when the latter have access to the same information. The retrieval step forces relevance filtering. The model never sees the noise.
The practical test: before adding more context to a failing prompt, try reducing context first. Strip it to the minimum required for the task. If quality improves, you were suffering from context inflation, not context insufficiency.
Multi-Agent Systems: Leverage or Theater?
Multi-agent systems are having a moment. Every AI framework now supports agent orchestration. Every architecture diagram has at least four agents.
Some of this is real leverage. A planner agent that breaks down requirements, a coding agent that implements, a reviewer that catches issues, a test agent that validates — when each agent has a narrow, well-defined scope, the division of labor creates genuine value.
But without strict scope boundaries, multi-agent systems become token multipliers.
Consider a common anti-pattern: a "researcher" agent that reads the entire codebase and summarizes it, followed by a "planner" agent that reads the researcher's summary and the codebase again to make implementation decisions, followed by a "coder" agent that reads both the plan and the codebase. Three agents, three full codebase reads. If the codebase is 40,000 tokens, you've just burned 120,000 tokens before a single line of code was written.
The right question for every agent you add isn't "what will this agent do?" It's "what information does this agent actually need, and how much does adding it reduce the work the other agents have to do?" If the agent reads the same inputs as an existing agent, it's probably generating expensive redundancy, not intelligence.
A useful heuristic: if you can't describe what an agent's output makes cheaper or unnecessary for downstream agents, you don't need the agent.
Five Changes That Reduce Token Spend — With Implementation Details
These aren't principles. They're specific, implementable changes.
1. Structured Decision Logs Instead of Raw History
Stop carrying raw chat history across sessions. After a working session, generate a structured summary: decisions made, rationale, constraints discovered, current state. 200-400 tokens of structured context replaces 20,000-40,000 tokens of raw history — and the structured version is actually more useful to the model because it's been filtered for relevance.
A basic template:
## Session Summary — [date]
Feature: [name]
Decisions made: [list]
Constraints discovered: [list]
Current state: [description]
Open questions: [list]
2. Fresh Chats Per Feature, Not Per Project
The "one long conversation" model feels efficient. It isn't. Separate unrelated problems into separate conversations. A feature implementation, a bug fix, and an architecture review should never share a context window. The overhead of providing a brief context summary at the start of each new chat is negligible compared to the token inflation of carrying unrelated history.
3. Smaller Models for Scoped Tasks
Not every task requires Sonnet or GPT-4. Code formatting, test generation for straightforward functions, docstring writing, simple refactors — these are Haiku or GPT-4o-mini tasks. In a mixed workload, routing appropriately can reduce inference costs by 60-80% with no quality loss on the routed tasks. The key is defining scope boundaries clearly enough that routing decisions are deterministic, not ambiguous.
4. Explicit Memory Schema, Not Implicit Accumulation
If you're building with memory systems (LangMem, MemGPT-style architectures, custom vector stores), define what gets stored explicitly. The common failure mode is storing everything and retrieving broadly, which reintroduces the noise problem at the retrieval layer. Store decisions, not discussions. Store outcomes, not reasoning traces. Set explicit TTLs — most context that's more than a week old is noise.
5. Specification Quality as a Cost Control
The cheapest token is the one you never need to spend. A vague requirement generates a wrong answer, a correction, a second attempt, and usually a third. A precise requirement with explicit constraints, acceptance criteria, and examples of what "wrong" looks like generates a right answer on the first pass. In my workflow, investing 15 minutes in a tight spec before opening an AI chat typically saves 30-45 minutes of iteration. That's not just time — it's 60-70% fewer tokens on complex features.
How We Operationalized This: The AISDLC Skill
The five changes above are practices. Practices only stick when they're built into the workflow itself — not left to individual discipline.
At our company, a team went further and formalized these principles into a complete process called AISDLC (AI-assisted Software Development Lifecycle) — a structured way of running every project so that context is always managed, decisions are always recorded, and the AI always starts each session from a clean, compressed state rather than accumulated noise.
Based on that team's process, I built it into a Claude Code skill so any project can adopt it with a single command.
The skill is called /setup and it's open source: github.com/ChanduKaranam/claude-sdlc-setup
What it does
Running /setup in any project triggers a structured onboarding sequence. It first detects your stack — language, framework, ORM, CI config — then runs a short interview about your branch strategy, team size, and conventions. It uses extended thinking to plan the scaffold, shows you the full file list for approval, and writes everything in one pass without overwriting files that already exist.
In about 5 minutes, it generates:
- A tailored
.claude/directory with hooks, surface-scoped rules, scoped agents, reusable skills, slash commands, andsettings.json - A
docs/scaffold with a tickets folder,STATE.md,PLAYBOOK.md,DESIGN.md, and an ADR template - A root
CLAUDE.md— an operating manual Claude reads at the start of every session
The pieces that directly address context debt:
STATE.md + /handoff and /resume-session commands — at the end of a session, /handoff writes a structured snapshot of decisions made, current state, and next actions to STATE.md. The next session starts with /resume-session, which loads that snapshot instead of raw history. 400 tokens instead of 40,000.
Surface-scoped rules — instead of loading the entire codebase as context for every question, Claude loads only the rules file for the surface being worked on (rules/api.md, rules/db.md, rules/web.md). Each file specifies the conventions, libraries, and constraints that apply to that surface only.
context-budget-nag hook — fires warnings at 50 and 80 tool calls within a session. A direct mechanical counter to the "keep going" instinct that turns conversations into 190,000-token monsters.
ADR template — every significant architectural decision gets recorded in a format Claude reads at session start. Decisions stop getting lost, reversed accidentally, or re-litigated because the AI didn't know they'd already been made.
How to install
# Windows
irm https://raw.githubusercontent.com/ChanduKaranam/claude-sdlc-setup/main/install.ps1 | iex
# macOS / Linux
curl -fsSL https://raw.githubusercontent.com/ChanduKaranam/claude-sdlc-setup/main/install.sh | sh
Then open any project in Claude Code and type /setup.
The skill is MIT licensed. It's now the first thing we install on any new codebase.
What We Should Actually Be Measuring
Most engineering organizations track AI spend at the invoice level: total tokens consumed, total cost, cost per developer. That's a financial metric. It doesn't tell you whether you're getting value.
More useful metrics:
Tokens per successful task completion — not just tokens spent, but tokens per task that produced a result you actually used. If your team spends 80,000 tokens per feature and only 20,000 of those lead to shipped code, you have a context efficiency problem.
Retry rate by context size — track how often prompts need to be retried and correlate it with context window size at the time of the request. If retry rate climbs sharply above 30,000 tokens of context, that's your signal to implement context compression.
Fresh chat frequency — if engineers are habitually starting fresh chats mid-feature to escape context bloat, that's a workflow signal, not a bad habit to correct. It's evidence that your AI tooling isn't managing context well enough.
The best AI teams aren't the ones spending the most tokens. They're the ones who know why every token was spent and can defend the spend.
The Underlying Problem
The field's collective mental model of AI context is still too simple: more in, better out.
Real AI systems behave more like human attention than like databases. A database query returns precisely what you ask for regardless of how much other data exists in the table. A language model's output quality is sensitive to what else is in the window — and dense, noisy windows produce worse reasoning even when the relevant information is present.
Good AI architecture means designing for relevance, not volume. It means treating token spend as a leading indicator of architectural quality, not just a cost line item. And it means building systems that stay focused rather than systems that accumulate.
The future won't belong to teams that use the most AI. It will belong to teams that use it precisely.
If you're seeing context debt in your AI workflows — high retry rates, mid-session quality drops, engineers starting fresh chats compulsively — I'd like to hear about it. The patterns are more consistent across teams than most people expect.