

This post responds to Adam Patarino’s article, “Every AI Subscription Is a Ticking Time Bomb for Enterprise”, which argues that today’s AI subscriptions often hide the real economics of enterprise usage. The core warning is directionally right, but the more useful question for engineering leaders is not just whether subscription prices will rise; it is how to redesign the AI stack so pricing shocks, vendor constraints, and compliance demands do not become existential architectural risks.
The deeper issue is that enterprise AI is moving from lightweight chat to agentic, always-on, workflow-embedded systems. As that shift happens, flat per-seat pricing becomes less representative of underlying compute cost, while internal model hosting becomes a serious strategic option rather than an experimental side project.
Why the original argument matters
Patarino’s central claim is that many AI subscriptions are effectively underpriced for heavy users because the visible license fee does not reflect the true cost of inference, especially once usage expands into coding agents, document analysis, and multi-step autonomous workflows. That broad thesis is supported by public vendor moves, most notably GitHub’s decision to move Copilot toward usage-based AI Credits because agentic workloads made the previous model economically hard to sustain.
The same concern shows up in enterprise research. KPMG reports that organizations are scaling AI spending quickly, but many still struggle to move from pilots to mature production systems because cost visibility, governance, and operating discipline lag behind adoption. Marketplace’s reporting on enterprise AI spend likewise notes that many organizations are only now recognizing how quickly usage can outgrow the assumptions embedded in flat-fee tooling.
That said, the “time bomb” framing can become too absolute if it is interpreted to mean every subscription is irrational or every enterprise should exit vendor-hosted models immediately. A more balanced reading is that AI pricing is likely to become more segmented, more usage-sensitive, and more explicit about premium inference, especially for agentic and high-volume tasks.
What the evidence actually supports
Several public signals validate the view that the market is moving away from simple unlimited-style AI pricing. GitHub’s documentation and reporting around Copilot’s new billing model make clear that heavier requests and agentic usage now consume a metered pool of credits rather than fitting neatly inside a flat subscription. Microsoft also prices Microsoft 365 Copilot as a premium enterprise add-on rather than a low-cost mass subscription, reinforcing the idea that high-value AI is being packaged separately from baseline software licenses.
At the infrastructure level, Goldman Sachs estimates that AI-related capital expenditure could reach about 765 billion dollars annually by 2026 and exceed 1.6 trillion dollars by 2031, driven by data center expansion and specialized hardware demand. Those numbers do not prove any one product is subsidized by a specific amount, but they do show that the industry is building against an enormous capital base that will eventually require more disciplined monetization.
The weaker part of the popular narrative is the precision of some cost claims. Assertions that a given power user “really costs” 200 to 400 dollars per month are usually scenario models, not audited enterprise-wide averages. In practice, usage distributions are uneven, model prices change rapidly, and vendors can reduce per-token cost even as total spend rises because user behavior becomes more intensive.
Why internal model hosting becomes strategically important
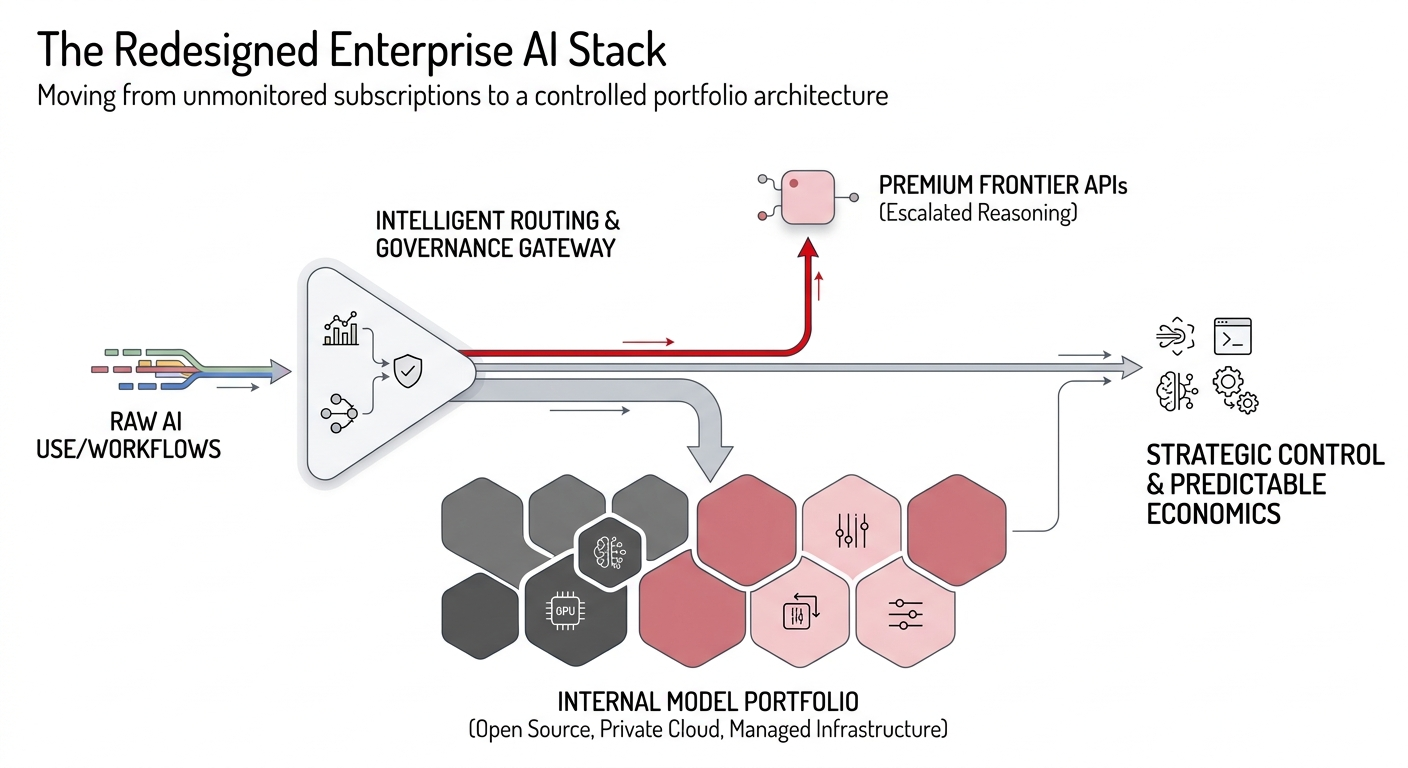
Once AI is treated as infrastructure rather than as a convenience feature, internal model hosting becomes a logical part of enterprise architecture planning. Internal hosting can mean several things: deploying open-source models in a private cloud, using managed model platforms such as Amazon Bedrock under the organization’s own AWS account, or exposing internally controlled inference endpoints that applications and developer tools consume through a shared API layer.
The strategic value comes from control. An internally hosted or internally governed model stack can improve data residency, tighten auditability, reduce dependency on one external provider, and create a predictable path for optimizing costs around high-volume workloads. For organizations building durable AI capabilities, that flexibility matters as much as raw token pricing because it changes who controls the roadmap, the security boundary, and the economics.
Internal hosting also matters because not every task requires a frontier model. Retrieval-augmented question answering, document summarization, code search, classification, and routine internal copilots often derive much of their value from domain context and workflow integration rather than from maximum benchmark performance. In those cases, a well-selected open-source model hosted internally can be good enough for most traffic while preserving the option to escalate harder tasks to external premium models.
The technical case for self-hosted and managed open models
The strongest argument for internal hosting is not ideology; it is workload shaping. When usage is sustained, predictable, and structurally repetitive, per-token external APIs can become economically unattractive relative to a reserved-capacity model hosted on GPUs that the organization already budgets as part of its cloud footprint. This is especially true for internal developer tooling, enterprise search, extraction pipelines, and high-volume support workflows where requests are numerous, latency matters, and the prompt patterns are stable.
Open models also create technical leverage. Teams can quantize, fine-tune, distill, or route requests across multiple model sizes depending on the task, which is much harder to do when the entire stack is mediated by a closed API with opaque internals. For researchers and systems engineers, this flexibility is not a minor feature; it is what allows the architecture to evolve around throughput, privacy, and cost targets rather than around whatever a vendor happens to expose this quarter.
Managed offerings such as Amazon Bedrock are especially relevant for teams that want internal control without running every layer from scratch. Bedrock can provide model access, enterprise security integration, and cloud-native governance within an AWS environment, while still allowing the organization to centralize policy and billing under its own account boundary. That does not make it “self-hosting” in the strictest sense, but it is often a practical intermediate point between pure SaaS dependence and full custom inference infrastructure.
The operational drawbacks are real
Internal hosting is not automatically cheaper, and it is often not simpler. Teams that self-host models inherit GPU utilization risk, autoscaling design, patching, evaluation, regression testing, observability, and performance tuning responsibilities that vendor-hosted APIs largely abstract away. For bursty or low-volume workloads, those burdens can easily overwhelm any notional token savings.
There is also a talent constraint. Running a serious inference stack requires people who understand serving frameworks, quantization trade-offs, memory limits, throughput tuning, and integration with identity, logging, and compliance systems. Organizations without that depth may end up with a fragile platform that is cheaper only on spreadsheets and more expensive in production incidents and engineering distraction.
Model quality is another trade-off. Open models have improved significantly, and many are strong enough for narrow enterprise tasks, but frontier proprietary models still tend to lead on difficult reasoning, broad coding support, and complex agentic behavior. That means internal hosting usually works best as part of a portfolio strategy, not as an all-or-nothing replacement for external AI vendors.
Where internal hosting makes sense first
The highest-value starting points are use cases with high volume, repeatable structure, and a strong need for privacy or predictable cost. Common examples include internal RAG systems over documentation and tickets, codebase Q&A for private repositories, standardized summarization pipelines, metadata extraction, and classification services behind internal business workflows.
These tasks share an important property: much of the intelligence comes from retrieval, orchestration, and context engineering rather than pure frontier-model reasoning. That makes them well suited to smaller or mid-sized open models, especially when paired with rerankers, retrieval pipelines, and domain-specific evaluation.
By contrast, the hardest engineering and research tasks often still benefit from external premium models. Deep refactoring across unfamiliar codebases, ambiguous architectural debugging, and high-stakes strategy generation often justify the extra cost of proprietary systems because the failure cost is larger than the inference bill. The practical architecture is therefore tiered: internal models for the broad base, frontier APIs for the difficult edge cases.
What this means for developer tools
For engineering teams, one of the clearest pressure points is AI-assisted coding. Community discussions indicate that Cursor operates as a multi-provider interface rather than a purely self-hosted environment, even when users bring their own keys, which means convenience does not necessarily equal full control over routing and data flow. Claude Code, by design, is tied to Anthropic-hosted models, which makes it powerful but also embeds the organization in a specific vendor’s economics and operating model.
That makes VS Code and custom extension paths especially important. Microsoft’s VS Code ecosystem has moved toward broader model choice and bring-your-own-key patterns, which creates room for organizations to build extensions or provider layers that route requests to internal endpoints first. A team can expose an internal code-assistant API backed by a self-hosted open model, then selectively escalate complex tasks to external premium models only when quality thresholds demand it.
Architecturally, that is one of the cleanest ways to reduce cost and concentration risk without sacrificing developer experience. The editor remains familiar, the routing policy becomes centrally governed, and the organization gains a realistic migration path away from pure subscription dependence.
A balanced architectural position
The strongest conclusion is not that subscriptions are bad or that self-hosting is always superior. The better conclusion is that enterprises need a portfolio approach: strong observability over AI usage, explicit cost models for agentic workflows, selective use of premium vendor-hosted models, and internal hosting where workload economics and governance requirements justify it.
That posture is more resilient than either extreme. It avoids naive dependence on under-instrumented flat-fee tools, but it also avoids romanticizing open-source hosting as a zero-cost escape hatch. For teams building long-term AI capabilities, the real objective is not to predict the exact future price of subscriptions; it is to build an AI stack that remains viable even when pricing, vendors, and model capabilities shift underneath it.
Why this matters now
The move from chatbot experimentation to embedded AI systems is forcing enterprises to confront a question that cloud teams learned years ago: who owns the economics of a capability once it becomes operationally essential. AI subscriptions were easy to adopt because they lowered friction, but the next phase will be defined by governance, routing, model mix, and infrastructure choices.
That is why internal model hosting deserves serious attention now. Not because every company should run its own frontier model cluster, but because organizations that understand where internal hosting fits into a layered architecture will be better positioned to control cost, protect data, and preserve optionality as the market moves beyond simplistic subscription assumptions.