

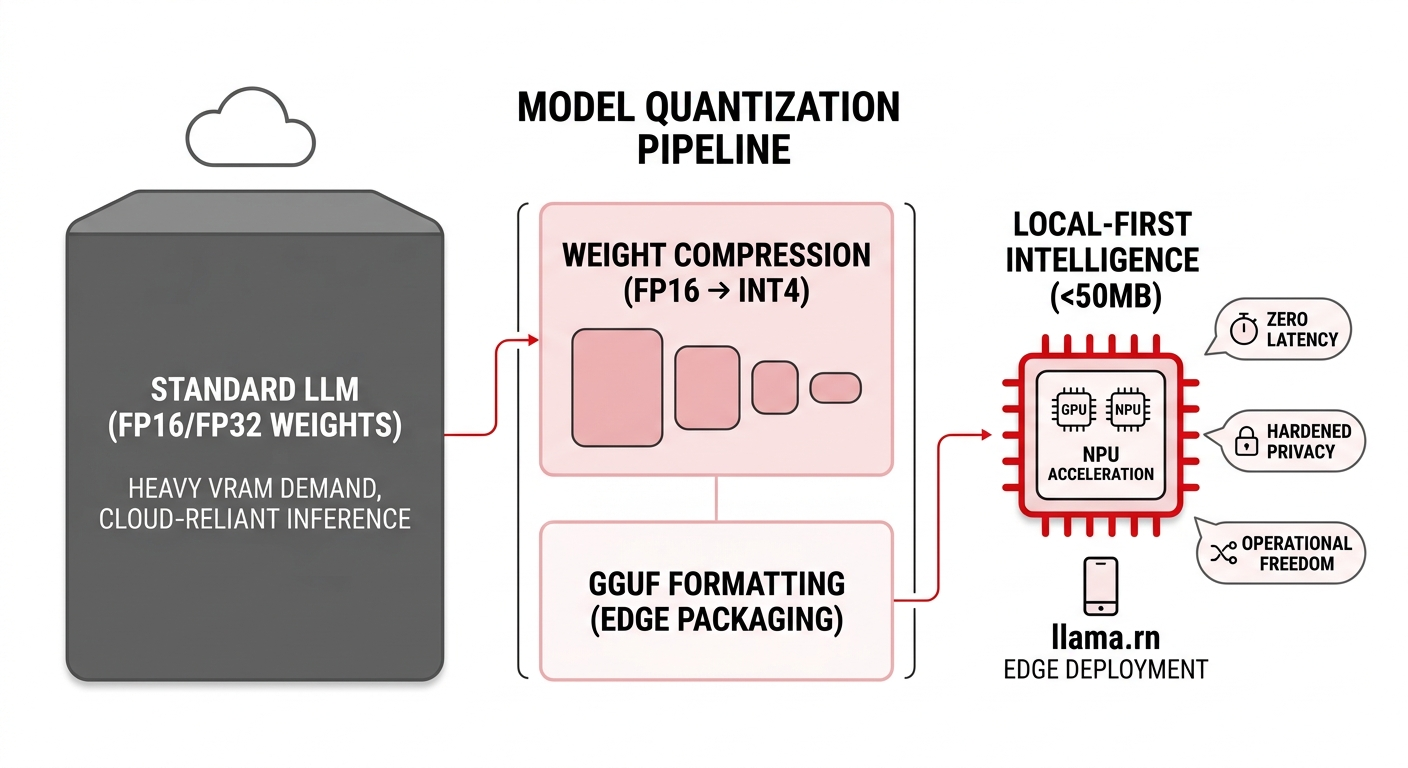
The Compute Bottleneck: Why Standard LLMs Fail at the Edge
In our recent architectural sprints, we’ve confronted the primary barrier to pervasive AI: the sheer resource cost of high-parameter models. Standard LLMs are typically stored in 16-bit or 32-bit floating-point precision ($FP16$ or $FP32$). While mathematically precise, these "heavy" weights result in models that demand massive VRAM and continuous server-side "engines" just to perform basic inference. For engineering teams building for mobile or edge environments, this memory footprint is the ultimate wall.
Quantization: Systems-Level Precision Reduction
Quantization is the mechanical process of mapping high-precision floating-point values to a lower-bitwidth integer space (typically $INT8$, $INT4$, or even $INT2$).
Rather than maintaining $0.123456789$, we "round" the weights into discrete levels. While this sounds like it would degrade model "intelligence," modern LLMs exhibit remarkable resilience to this compression. The core semantic logic of the model remains intact, allowing for a 70-80% reduction in memory footprint with minimal impact on perplexity.
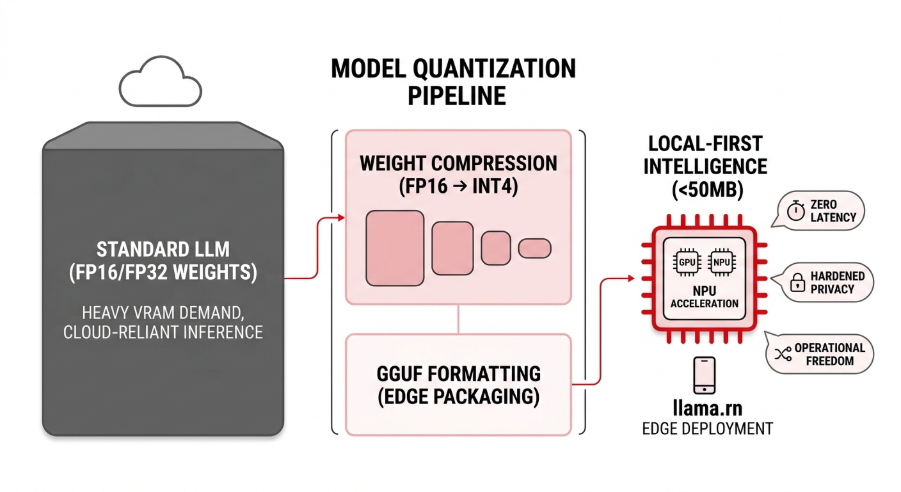
Operationalizing the Edge with llama.rn and GGUF
To move from theory to production, we leverage llama.rn (a high-performance React Native wrapper for llama.cpp) to handle inference directly on the device. This allows us to utilize the GGUF format, which is purpose-built for edge deployment:
- Hardware Acceleration: llama.rn maps quantized workloads to the device’s GPU and NPU, bypassing the latency of CPU-only execution.
- Memory Efficiency: By utilizing 4-bit quantization, we have successfully deployed functional models with footprints under 50MB.
- Proof-of-Work: In our internal testing, these models parse natural language, manage context windows, and calculate complex shared expenses—all while consuming less space than a standard high-quality audio file.
The Strategic Shift: Moving to "Local-First" AI
This transition from "Big Cloud AI" to "Local-First AI" isn't just an optimization; it's a fundamental change in application architecture:
- Zero-Latency Inference: By eliminating the round-trip to a server farm, responses become near-instant.
- Hardened Privacy: When the weights live 100% on the user’s hardware, sensitive data never leaves the device, removing the need for external APIs and the associated security risks.
- Operational Freedom: Applications remain functional in zero-connectivity environments, ensuring reliability regardless of network availability.
Engineering Conclusion
Quantization proves that engineering credibility is often found in what you can trim away. By prioritizing operational realism and implementation maturity over cloud-reliant hype, we are building a new class of "Smart, Tiny AI" that is fast, private, and scalable.
The infrastructure for local intelligence is here. Are you ready to deploy it?