

The Problem With "Generic" AI
Imagine you hired a brilliant new employee. They graduated top of their class, can discuss almost any topic, write emails, summarise reports, and answer questions faster than anyone you've ever met.
But there's a catch: they sound like a textbook. Their emails are polished but feel copy-pasted. Their summaries are accurate but miss the nuance your team cares about. They keep using the wrong terminology for your industry. And no matter how many times you correct them, they revert to their old habits the next day — because they have no memory of your feedback.
That is a general-purpose AI model out of the box.
Fine-tuning is how you fix it.
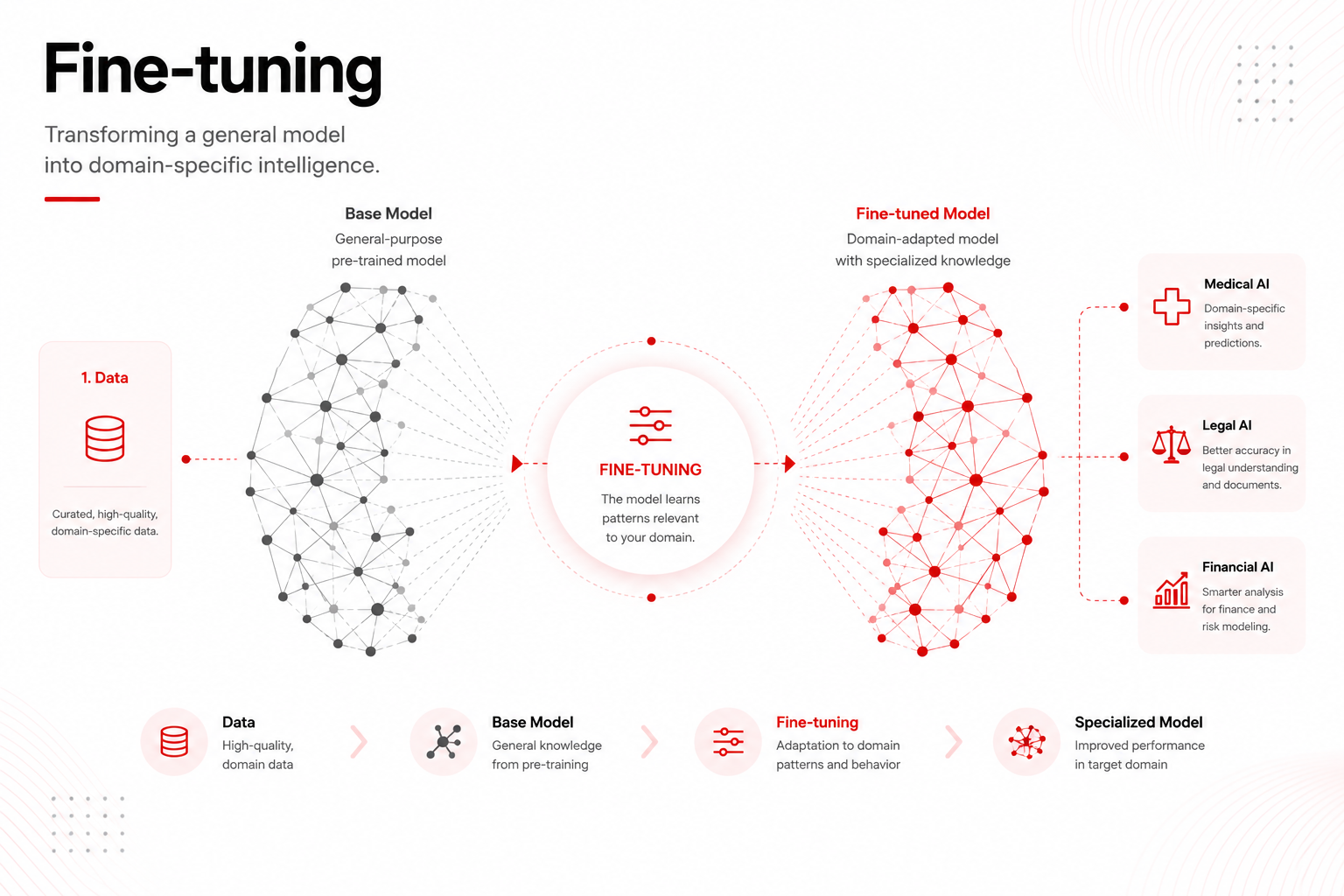
What Is Fine-Tuning?
Large language models (LLMs) like GPT-4, Claude, or Mistral are trained on billions of web pages, books, and articles. This training gives them broad knowledge about almost everything. But broad is not the same as yours.
Fine-tuning is additional training performed on top of that base knowledge — using your specific data, your tone, your domain, or your task. The model keeps everything it already knows but gets re-shaped to fit your use case.
Think of it like this:
A chef trained at culinary school knows hundreds of cuisines. Fine-tuning is like that chef spending six months in your grandmother's kitchen, learning her exact recipes, her seasoning preferences, and the way she describes every dish.
They don't forget how to cook French food. They just become really good at cooking like your grandmother.
The Three Layers of "Teaching" an AI
Before we go deeper, it helps to understand that there are actually three ways to teach an AI something new — and fine-tuning is only one of them:
| Method | What You Give It | When It Learns | Remembers After? |
|---|---|---|---|
| Prompting | Instructions in the chat window | Each conversation | No |
| RAG (Retrieval-Augmented Generation) | A document library it searches at runtime | At retrieval time | Documents persist, not learning |
| Fine-tuning | Labelled examples of the behavior you want | During a dedicated training run | Yes — baked into the model weights |
A real-world system might use all three at once — and often does. We'll look at a concrete example of this later.
Why Do You Need Fine-Tuning?
1. Tone and Voice Consistency
General models write in a "neutral internet voice." If your brand has a specific style — sharp and data-driven, warm and conversational, technical but accessible — a general model will drift from it constantly, no matter how many times you prompt it.
Fine-tuning locks the voice in. After fine-tuning on 50–200 examples of your writing, the model defaults to your style without being told.
2. Domain-Specific Knowledge
General models know a little about everything. If you work in biotech, derivatives trading, or industrial manufacturing, the model will often use imprecise terminology, get acronyms wrong, or conflate concepts that experts would never confuse.
Fine-tuning on domain text raises the baseline. The model stops treating your field like a Wikipedia article and starts thinking like a practitioner.
3. Task Specialisation
Some tasks are too specific to describe well in a prompt. For example:
- "Extract the product names, quantities, and delivery dates from these shipping manifests"
- "Classify this customer review as Billing / Delivery / Product Quality / Other"
- "Generate a subject line for this email in under 8 words that includes the customer's first name"
You could write a 500-word prompt explaining each rule. Or you could show the model 200 examples of input → correct output and let it learn the pattern. Fine-tuning is almost always more reliable for structured extraction and classification tasks.
4. Cost and Speed at Scale
A fine-tuned smaller model can often match a large general model on your specific task — at a fraction of the API cost and latency. Fine-tuning a Mistral 7B model on your task and deploying it yourself can be 10–100× cheaper per call than using GPT-4 for the same task.
5. Privacy
Fine-tuning lets you train on proprietary data once, then use a self-hosted model. You stop sending sensitive documents to a third-party API on every single request.
How Does Fine-Tuning Actually Work?
The Conceptual Idea
A neural network is a giant web of numbers called weights. Training is the process of adjusting those weights so the model gets better at predicting what token comes next. Pre-training adjusts billions of weights across billions of examples — it's enormously expensive (millions of dollars).
Fine-tuning runs the same adjustment process but:
- Only on your small dataset (hundreds to tens of thousands of examples)
- For a small number of passes (epochs)
- Sometimes only adjusting a subset of the weights (more on this below)
This is computationally cheap by comparison. A fine-tuning run that would cost $1M to do from scratch might cost $10–$100 with the right technique.
What Does a Fine-Tuning Dataset Look Like?
For most use cases, you need instruction-following pairs: a prompt (what the user asks) and the ideal response (what the model should say).
Think of it like a training manual. Each entry says: "When someone asks this, the perfect answer is that." You provide enough of these examples to cover the range of situations your model will face — typically 50–500 pairs for style or tone tasks, and 200–5,000+ for more complex classification or extraction tasks.
The quality of each example matters far more than the quantity. A dataset of 100 carefully written, consistent examples will produce a better model than 1,000 mediocre ones.
Here's what a single training example looks like in the standard JSONL format:
{
"messages": [
{
"role": "system",
"content": "You are a writing assistant for a technical blog. Match the author's voice: direct, data-driven, no filler."
},
{
"role": "user",
"content": "Write an intro for a post about fine-tuning LLMs for expense parsing."
},
{
"role": "assistant",
"content": "Expense descriptions are chaos. 'Grabbed drinks, split it 4 ways except Jake who had water' is not a structured record — it's a sentence your finance tool needs to parse. General models can read it. Fine-tuned models can reliably extract it."
}
]
}
Each line in the file is one complete example. Your training file is just hundreds of these stacked together.
Modern Fine-Tuning Techniques
Full Fine-Tuning
All model weights are updated. Most expensive, most powerful. Requires significant GPU memory (e.g., 80GB+ for a 7B parameter model in full precision).
LoRA (Low-Rank Adaptation)
The most popular technique today. Instead of updating all weights, LoRA inserts small trainable "adapter" matrices into specific layers. Only 1–10% of the parameters are trained, but results approach full fine-tuning quality for most tasks. Runs on a single consumer GPU for smaller models.
QLoRA
LoRA but with quantised (compressed) weights for the base model. Makes fine-tuning a 7B model possible on a single 16GB GPU. Used heavily in the open-source community.
RLHF (Reinforcement Learning from Human Feedback)
The technique behind ChatGPT's "be helpful, be harmless" training. Human raters score model outputs; those scores train a reward model; the reward model guides further training. More complex and expensive than supervised fine-tuning, but produces models that are better at following nuanced human preferences.
Fine-Tuning vs. RAG: Which Should You Use?
This is the most important practical question in AI engineering right now.
| Situation | Use RAG | Use Fine-Tuning |
|---|---|---|
| Your knowledge changes frequently (news, product catalog) | ✅ | ❌ |
| You need to cite sources | ✅ | ❌ |
| You want specific style / tone | ❌ | ✅ |
| You need structured output from free-form input | ❌ | ✅ |
| Your dataset is 50–500 examples | ❌ (not enough) | ✅ |
| You need low latency at high volume | ❌ | ✅ |
| Your data is sensitive and can't leave your servers | Depends | ✅ (self-hosted) |
The honest answer: most production systems use both.
A Real-World Example: Splitwise
Splitwise is an app that helps groups of people split bills and track shared expenses. On the surface it sounds simple — but the messiness of how people describe money makes it a perfect fine-tuning use case.
The problem with a general model:
People describe expenses in wildly inconsistent ways. "Grabbed dinner for the team, $94 total, split 5 ways but Jake only had drinks so make it $12 for him and the rest split 4 ways." A general LLM can understand that sentence, but reliably extracting a structured breakdown — names, amounts, splits — requires careful prompt engineering that still breaks on edge cases.
Where prompting falls short:
You could write a detailed system prompt describing every rule. But expense language is endlessly creative. Users type in shorthand, use nicknames, forget currency symbols, mix multiple transactions in one message. No prompt is long enough to cover every variation.
Where fine-tuning wins:
Train the model on 500–1,000 real examples of messy expense descriptions paired with their correct structured output. The model learns the pattern — not just the rules. It handles nicknames, missing currencies, partial splits, and ambiguous phrasing because it has seen similar cases before, not because someone wrote a rule for each one.
A training pair for this might look like:
{
"messages": [
{
"role": "user",
"content": "Grabbed dinner for the team, $94 total, split 5 ways but Jake only had drinks so make it $12 for him and the rest split 4 ways"
},
{
"role": "assistant",
"content": "{\"total\": 94, \"currency\": \"USD\", \"splits\": [{\"name\": \"Jake\", \"amount\": 12}, {\"name\": \"others\", \"count\": 4, \"amount\": 20.5}]}"
}
]
}
After seeing hundreds of these, the model stops needing the rulebook — it recognises the shape of the problem.
Where RAG fits alongside it:
Group history — who usually pays for what, standing splits between roommates, recurring expenses — is perfect for RAG. That context changes over time and is specific to each group. You retrieve the relevant history and pass it to the (fine-tuned) model at query time. Fine-tuning handles the language understanding; RAG handles the personal context.
This combination is the template for almost any AI feature built on top of user-generated, informal text.
How to Fine-Tune a Model: A Practical Walkthrough
Here's how you would actually do this, from zero to deployed.
Step 1: Define the Task Precisely
Fine-tuning works best when the task is narrow and well-defined. Bad: "make the model smarter." Good: "given a trend summary and 3 user questions, generate a 200-word LinkedIn post in this author's voice."
Step 2: Collect and Prepare Training Data
- Minimum: 50–100 high-quality examples for style/tone tasks
- Better: 200–500 for structured tasks
- Ideal: 1,000+ for production-grade reliability
- Format as instruction-response pairs (JSONL is the standard)
- Split into train / validation (80/20 or 90/10)
- Clean aggressively: remove duplicates, fix formatting, remove any examples where the output is wrong
Step 3: Choose Your Base Model
Common starting points:
| Model | Parameters | Good For |
|---|---|---|
| Mistral 7B | 7B | General tasks, fast to fine-tune, open weights |
| Llama 3.1 8B | 8B | Strong baseline, well-documented fine-tuning guides |
| Phi-3 Mini | 3.8B | Low-cost inference, strong reasoning per parameter |
| GPT-3.5 Turbo | ~20B | Managed fine-tuning via OpenAI API, no GPU needed |
| Claude (Haiku) | — | Managed fine-tuning (Anthropic, limited access) |
For most teams: start with a managed service (OpenAI or Together.AI) for speed, then move to self-hosted when scale justifies it.
Step 4: Run the Fine-Tuning Job
Option A — Managed (easiest):
Platforms like OpenAI, Together.AI, and Fireworks let you upload your training file through a dashboard or simple API call. No GPU required, no infrastructure to manage. You upload your dataset, pick a base model, set the number of training passes, and the platform handles the rest. A typical run finishes in minutes to a few hours and gives you a model endpoint you can immediately swap into your application.
from openai import OpenAI
client = OpenAI()
# Upload your training file
file = client.files.create(
file=open("training_data.jsonl", "rb"),
purpose="fine-tune"
)
# Start the fine-tuning job
job = client.fine_tuning.jobs.create(
training_file=file.id,
model="gpt-3.5-turbo",
hyperparameters={"n_epochs": 3}
)
print(job.id) # poll this until status == "succeeded"
Option B — Self-hosted with LoRA (more control):
If you want full ownership of the model weights or are training on sensitive data, run fine-tuning on your own hardware using the Hugging Face ecosystem (the transformers, peft, and trl libraries). With QLoRA you can fine-tune a 7-billion-parameter model on a single GPU with 16GB of memory — the same spec as a modern gaming laptop. The trade-off is more setup: you manage the infrastructure, versioning, and serving layer yourself.
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
from peft import LoraConfig, get_peft_model
# Load the base model in 4-bit (QLoRA)
bnb_config = BitsAndBytesConfig(load_in_4bit=True)
model = AutoModelForCausalLM.from_pretrained(
"mistralai/Mistral-7B-v0.1",
quantization_config=bnb_config,
device_map="auto"
)
# Attach LoRA adapters — only ~1% of weights will be trained
lora_config = LoraConfig(r=16, lora_alpha=32, target_modules=["q_proj", "v_proj"])
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# trainable params: 8,388,608 || all params: 3,752,071,168 || trainable%: 0.22
The rest of the training loop uses the trl SFTTrainer and looks like any standard PyTorch training script.
Step 5: Evaluate Before You Ship
Never deploy a fine-tuned model without evaluation:
- Held-out test set — examples the model never saw during training. Measure accuracy, format compliance, or whatever metric fits your task.
- Side-by-side comparison — show 20 outputs from the base model and 20 from the fine-tuned model to someone unfamiliar with which is which. Which is better?
- Regression check — make sure the model hasn't forgotten how to do things it did well before. Fine-tuning can cause "catastrophic forgetting" if you overtrain.
Step 6: Deploy and Monitor
Serve the model via an API (vLLM, Ollama, or a managed endpoint) and swap it into your application the same way you'd swap any model. Monitor output quality over time — model drift is real, and you may need to re-fine-tune as your data evolves.
Common Mistakes to Avoid
Too little data, too many epochs. If you fine-tune on 30 examples for 10 epochs, the model memorises those examples instead of learning the pattern. Use more data, fewer epochs.
Dirty training data. One bad example can teach the model a bad habit that takes 50 good examples to counteract. Curate your data carefully.
Fine-tuning when prompting would work. If a well-crafted system prompt gets you 90% of the way there, fine-tuning for the last 10% may not be worth the cost and complexity. Try prompting first.
Ignoring the base model's strengths. Don't fine-tune safety out of a model to make it "more helpful." You'll create something brittle and hard to reason about. Work with the model's guardrails, not against them.
Not versioning your training data. Your fine-tuned model is only as good as the data it was trained on. Treat training data like code — version it, review it, and document why each example is in there.
Summary
| Question | Answer |
|---|---|
| What is fine-tuning? | Additional training on your specific data that shapes a general model's behavior to fit your use case |
| Why use it? | Consistent voice, domain accuracy, task specialisation, cost efficiency, privacy |
| When NOT to use it? | When RAG or prompting is sufficient; when your data changes frequently |
| What technique should I start with? | LoRA / QLoRA for self-hosted; managed API fine-tuning for fastest time to production |
| How much data do I need? | 50–500 examples for style tasks; 200–5,000+ for classification or extraction |
Fine-tuning is not magic — it is systematic curation. The better your examples, the better the model. Start small, measure rigorously, and iterate. The teams getting the most out of fine-tuned models are the ones who treat training data as a first-class engineering asset, not an afterthought.
Fine-tuning is not a silver bullet — but for the right problem, it is the sharpest tool available. Start with a clear task, invest in your training data, and let the model do the rest.