

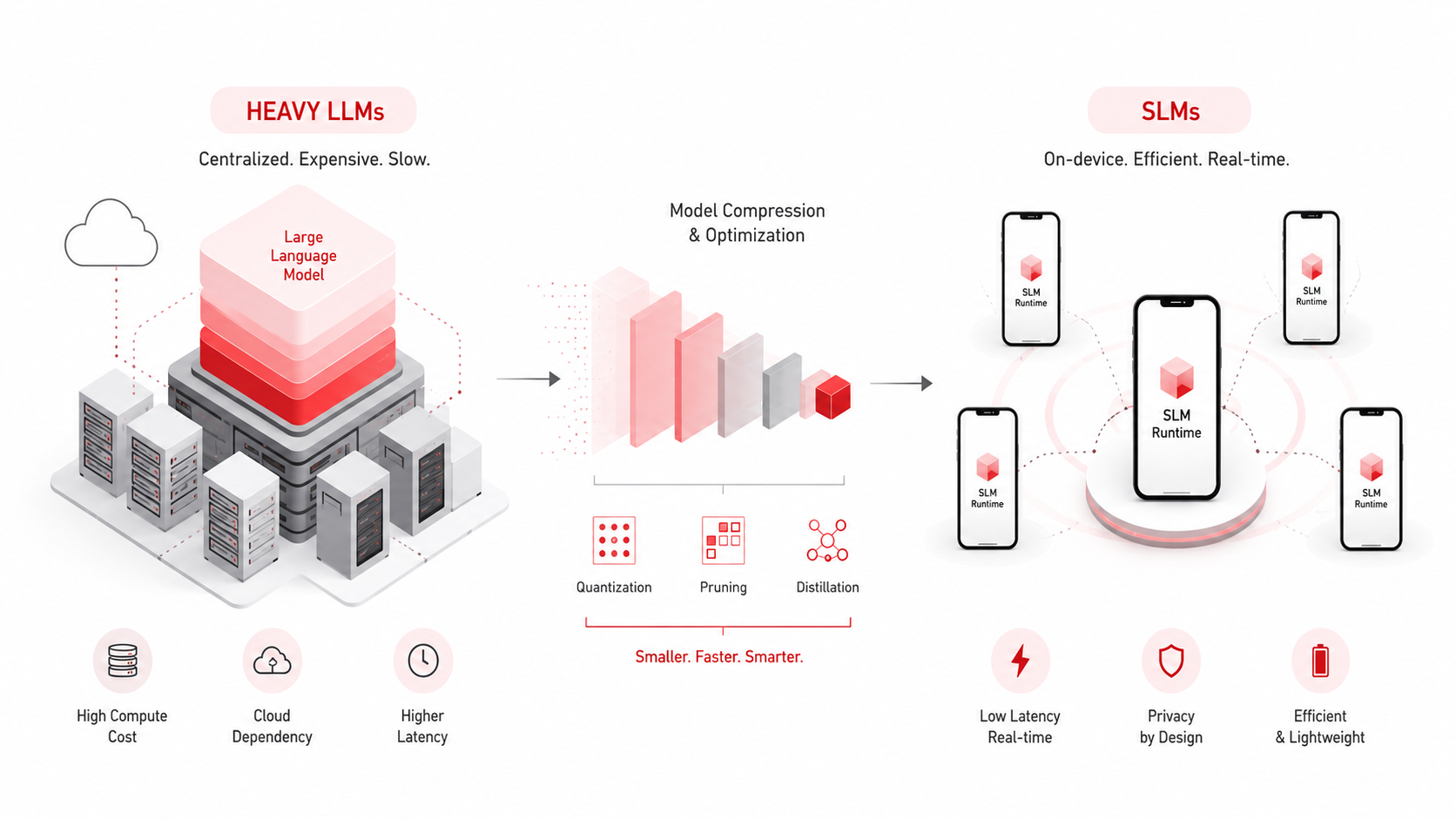
Headline caveat: SLMs are not a universal substitute for frontier LLMs. In production mobile, they increasingly own the workloads that matter for retention fast, frequent, privacy-sensitive, and offline-capable while heavy models stay on the escalation path. This post is written for technical decision-makers who care about implementation maturity and operational realism, not vendor hype.
Framing the problem as a system, not a model pick
A cloud-hosted 70B-class model can score well on demos. On mobile, the product is the full system: transport, auth, retries, rate limits, cold starts, token accounting, safety filters, and what happens when the user is on 2G in an elevator. Engineering credibility comes from designing for that envelope.
· User-visible latency is dominated by tail behavior (p95/p99), not mean response time.
· Cost scales with successful adoption; unbounded inference paths convert growth into infra risk.
· Compliance and incident response are easier when sensitive text never leaves the device for routine tasks.
What counts as an SLM in a mobile engineering context
There is no single industry line in parameters. Practically, teams treat “small” as whatever fits a mobile SLO bundle: cold-load time, steady-state RAM, thermal budget, and update size. That often lands in roughly tens of millions to low single-digit billions of parameters after compression always verified on target devices, not on a lab GPU alone.
How teams actually shrink and specialize models
· Distillation or supervised fine-tuning from a larger teacher so the small model mimics task-specific behavior.
· Post-training quantization (e.g., INT8, INT4 weight formats) paired with kernel/runtime support on the SoC.
· Architecture choices that favor inference (grouped query attention, smaller vocabularies where safe, shorter context windows aligned to the product).
· Task decomposition: classification, extraction, and rewrite as separate heads or smaller specialists instead of one general chat endpoint.
Proof-of-work: where this shows up in real stacks
On-device inference today is typically wired through vendor or cross-platform runtimes examples teams actually integrate include Core ML on iOS, NNAPI / GPU delegates on Android, ONNX Runtime Mobile, ExecuTorch, MediaPipe LLM Inference API, or GGUF pipelines via llama.cpp-style bindings. The credible answer is never “we plugged in AI”; it is which runtime, which build flags, and which devices were in the acceptance matrix.
Where heavy LLM-first mobile designs fail in production
1) Distribution and on-device artifact lifecycle
Shipping multi-gigabyte weights inside an APK is rarely acceptable. Post-install download improves install size but creates a second product: resumable downloads, checksum verification, storage pressure on 64 GB devices, migration when you bump tokenizer or schema, and rollback when a bad build slips out.
2) Memory, thermals, and foreground time
Sustained decode on CPU or GPU raises skin temperature and drains battery. If your assistant runs in the keyboard or camera pipeline, you are competing with other foreground work. SLMs win when they are sized so inference stays inside a defined duty cycle per session.
3) Network and API coupling
Outages, quota errors, and regional latency spikes become P0s. Incident playbooks for “model provider degraded” are harder to sell to users than graceful degradation to a smaller local model plus a clear “try again when online” path.
4) Unit economics at scale
Per-token pricing is easy to model in a spreadsheet; production spend includes retries, overlong contexts, prompt injection attempts, and abuse. A hybrid design caps the blast radius by bounding cloud calls.
The architecture pattern that passes engineering review
Treat on-device SLM inference as the default data plane for high-frequency, low-risk tasks. Use cloud LLMs as a control-plane or escalation tier for low-frequency, high-complexity tasks with explicit policy, budget, and logging.
A concrete routing loop
- Local intent and risk classifier (rules + small model): domain allowed? PII present? payment/legal risk?
2. If bounded task with high confidence: run SLM; enforce max tokens and structured output schema.
3. Validate output (JSON schema, arithmetic for money, date parser sanity). On failure: one repair prompt or deterministic fallback.
4. Escalate to cloud LLM only when confidence low, task explicitly open-ended, or retrieval corpus requires scale you do not host on-device.
Systems-thinking checkpoint: the SLM is one component. Reliability comes from validators, retrieval (local embeddings + tiny vector store for help docs), feature flags, and model versioning tied to app releases.
Quantization and runtimes: operational depth
Quantization reduces weight footprint and memory bandwidth pressure. The implementation maturity bar is regression testing on your own prompts and locales, not a single perplexity number.
· INT4 weights can win size but amplify numeric and formatting errors; finance and scheduling flows need extra validation.
· Kernel fusion and delegate selection (NPU vs GPU vs CPU) change latency more than parameter count alone.
· You need golden-file tests for structured outputs and red-team prompts for injection and jailbreak paths that hit the small model first.
Use cases where SLMs are the right default
In-app support and onboarding
Ground answers with retrieval over your docs; refuse or hand off when retrieval confidence is low. The SLM summarizes and routes; it does not invent policy.
Expense and money-adjacent flows
Use the model for normalization and categorization; use code for balances. User confirmation before any irreversible action is non-negotiable.
Keyboard, rewrite, and drafting aids
Short context, tight max tokens, immediate undo. Ideal SLM territory.
Voice and command routing
Intent classification and slot filling on-device; execution through typed app actions reduces hallucinated “API calls.”
Decision table: SLM-first hybrid vs LLM-first cloud
Prefer SLM-first hybrid when
· Tasks are frequent, templatable, or schema-bound.
· You have latency or offline SLOs.
· You must minimize data egress for privacy or contract reasons.
· You need predictable cost per daily active user.
Stay LLM-first cloud when
· The product truly needs open-domain reasoning and long context every session.
· You can operate mature observability, safety, and spend caps, and users accept variable latency.
What to instrument before Ghost or any public launch
Leadership and technical evaluators both reward operational realism. Ship dashboards, not adjectives.
· p50/p95/p99 end-to-end latency from user action to rendered result.
· Task success and undo/correction rates segmented by device tier.
· On-device vs cloud fallback rate and top failure reasons (low confidence, validation, timeout).
· Cost per successful task, including client retries and server-side safety filters.
· Safety and abuse metrics with incident IDs tied to model version and prompt template hash.
Closing
Small language models are not “winning” because they beat frontier models on bench scores. They are winning because they let teams ship mobile AI that survives constraints: networks, batteries, storage, privacy, and finance. The credible path is hybrid, validated, and measured not all on-device, not all in the cloud, but deliberately split by risk and frequency.