

Most people interact with AI through text. You type something, the AI types back. It feels like a conversation, and the underlying technology — large language models — has become almost familiar.
But there's another side of AI generation that works completely differently: video. AI-generated videos are everywhere now — talking avatars, animated faces, synthetic presenters. And the technology behind them shares almost nothing with how ChatGPT writes your emails.
I've been contributing to an open-source project called SoulX-FlashTalk — a system that takes a photo of a person and an audio clip, and generates a video of that person speaking in real time. Working on it changed how I think about AI generation entirely. This post is what I learned, written for anyone curious — whether you build AI systems for a living or you've just wondered how those talking-head videos actually work.
What Happens When an AI Writes Text
Let's start simple.
When a language model like ChatGPT generates text, it works one word at a time. It reads everything it's written so far, predicts the most likely next word, writes it down, then repeats. Like a very fast typist who never looks ahead — only backward at what's already on the page.
The words themselves come from a fixed dictionary of about 100,000 options. At each step, the model picks one. That's it. One choice from a list, repeated thousands of times, producing what reads like coherent thought.
This matters for two reasons. First, each step is computationally cheap — one forward pass through the model produces one word. Second, the output appears instantly and progressively. You can watch the words stream in character by character. If the model takes a wrong turn at word 50, word 51 is still valid text — it just might not be the best possible continuation. Errors degrade quality, but they don't break things visually.
For engineers: this is autoregressive generation with causal (unidirectional) attention masking. Each position attends only to past positions. The output space is discrete — token IDs sampled from a probability distribution over the vocabulary. Inference cost scales linearly with sequence length.
What Happens When an AI Generates Video
Now imagine a completely different problem.
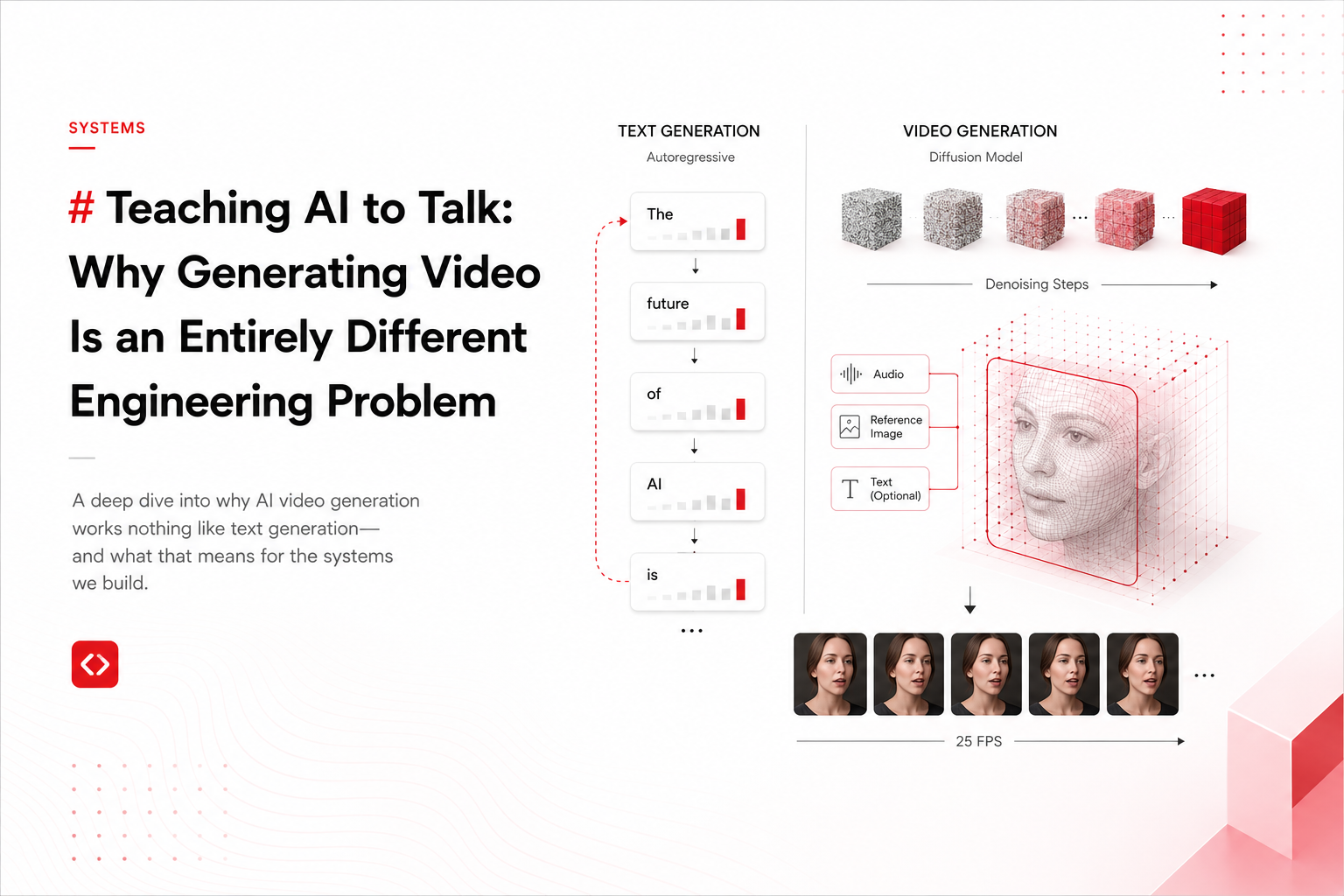
Instead of choosing the next word from a list, you need to produce a picture. Not one picture — 25 pictures per second, each one slightly different from the last, depicting the same person from the same angle with the same lighting, and their mouth has to match the audio perfectly.
The first difference: there is no dictionary. A single video frame at standard quality is a grid of roughly 410,000 pixels, each with three color values. The number of possible frames is effectively infinite. The model isn't choosing from a list — it's painting from scratch, every single frame.
The second difference: everything is connected to everything. In text, word 5 and word 50 might be loosely related. In video, pixel (100, 200) in frame 12 and pixel (101, 200) in frame 13 are the same spot on someone's face one-twenty-fifth of a second later. If those two pixels don't match, you see a flicker. Our eyes catch these inconsistencies instantly — much more aggressively than our reading comprehension catches a slightly awkward word choice.
No AI model can work with raw pixels at this scale. So video generation uses a trick: before the AI does anything, a compression system (called a VAE) squishes the video down dramatically. In SoulX-FlashTalk, the compression factor is 4×8×8 — four times smaller in time, eight times smaller in each spatial direction. The AI model works in this compressed space, generating a tiny mathematical representation of each frame, and the VAE then unpacks it back into actual pixels.
The generation itself uses a technique called diffusion. Instead of predicting the next word, the model starts with television static — pure random noise — and gradually cleans it up, step by step, until a coherent video appears. Each cleanup step requires running the entire model forward. A typical generation might need 20 to 50 of these passes to produce a few seconds of usable video.
For engineers: the generator is a Diffusion Transformer (DiT) operating in the VAE's latent space. Attention is 3D — spatial × spatial × temporal — making the effective sequence length orders of magnitude longer than typical LLM contexts even after compression. The denoising schedule, conditioning signals (audio, reference image, text), and noise parameterization are all architectural decisions with direct quality impact.
Why Video Generation Is a Fundamentally Harder Problem
These aren't different scales of the same thing. They're different problems that share some vocabulary.
You can't show half a result
When an LLM streams text, every word it produces is immediately useful. You can read along as it types. The generation unit is one word.
Video can't do this. You can't show half a frame. You can't show one frame that hasn't been made consistent with the next one — if you do, you get a flicker. The minimum useful unit of video generation is a chunk: a small batch of frames (typically a fraction of a second) that are internally consistent. The entire chunk has to be ready before any of it reaches the screen.
This creates a double latency requirement that doesn't exist for text: you need fast startup (time to the first chunk) and fast throughput (continuous chunks fast enough to maintain smooth video). Both must clear perceptual thresholds simultaneously.
Errors compound visually
If a language model makes a bad prediction at word 50, word 51 is built on that mistake, but the conversation still makes sense. Text degrades gracefully.
Video doesn't. Each new chunk of video is built using the previous chunks as visual reference. If chunk 5 has a slightly off skin tone, chunk 6 conditions on that error and might make it worse. By chunk 20, the face might look nothing like the original person. This is called drift, and in bad cases, visual collapse — the output degrades into incoherent noise.
This problem doesn't exist in text generation because words don't have the same kind of dense, high-dimensional physical consistency requirements. A slightly wrong word doesn't change the color of all subsequent words.
The computational cost is in a different league
Generating one word with an LLM: one model forward pass.
Generating one second of video with a diffusion model: potentially 25–50 forward passes through a model that is processing 3D data (space × space × time) rather than a 1D sequence of words. And the VAE encoding and decoding — the compression and decompression of every frame — is a separate cost on top.
For engineers: the attention complexity is O(n²) in sequence length, but the effective sequence length for video is vastly larger than for text. Even after 4×8×8 VAE compression, a one-second 480p clip produces a latent tensor that, when flattened for attention, exceeds most LLM context windows. This is why architectural choices about what attends to what — not just model size — dominate video generation quality.
SoulX-FlashTalk: What I Worked On
SoulX-FlashTalk is a 14-billion-parameter model for generating talking-head video from audio. You give it a single photo of a person and an audio recording, and it produces a video of that person speaking — lip-synced, with natural head movement and facial expressions — in real time.
It was built by the Soul AI Lab team and open-sourced. I contributed to parts of the community release — working on inference infrastructure and getting close enough to the pipeline to understand where the real engineering problems are.
Here's the architecture, explained in layers.
The Big Idea (for everyone)
Previous systems that generated talking-head video in real time had a design choice that seemed necessary: to generate video fast enough for streaming, the AI could only look backward at what it had already created. It couldn't look ahead or sideways. Think of it like writing a story where you can only see the previous sentence — you can't read back the whole paragraph to check if your current sentence makes sense with it.
SoulX-FlashTalk questioned that assumption. Their insight: the model generates video in small chunks, maybe a fraction of a second at a time. Within each chunk, the model can look at all the frames together — backward and forward. It only needs the "backward-only" constraint between chunks. This sounds like a minor difference, but it's the difference between a model that understands each fraction of a second as a coherent scene versus one that is guessing each frame without seeing its immediate neighbors.
The result: better motion quality, more natural expressions, and — counterintuitively — simpler and faster training.
The Architecture (for engineers)
The model has four main components.
The Compressor (3D VAE): Takes raw video frames and compresses them into a much smaller mathematical representation. Compression factor is 4×8×8 — the time dimension gets 4× smaller, each spatial dimension gets 8× smaller. This is what makes it feasible for the main model to process video at all. The same compressor runs in reverse to turn the model's output back into actual video frames.
The Generator (Diffusion Transformer — DiT): This is the 14-billion-parameter core. It's built on the WAN2.1 architecture. Each transformer block has 3D attention layers that process spatial and temporal dimensions together, cross-attention layers that condition on the reference image and text, and a separate audio cross-attention layer that injects the speech signal.
The key design choice: attention within a chunk is bidirectional — every frame in the chunk can attend to every other frame. Between chunks, attention is unidirectional — each chunk can only see previous chunks, not future ones. This preserves the streaming capability (you can generate chunk by chunk) while maintaining spatial coherence within each chunk.
The Conditioning System: Three types of input condition the generation. Audio comes through a Wav2Vec model that converts speech into a sequence of embeddings. A reference image is processed through CLIP (for semantic understanding) and the VAE encoder (for visual features) to maintain identity consistency. Text captions go through a multilingual text encoder. These all feed into the DiT through separate cross-attention pathways.
The Latent Input Assembly: For each generation step, the model receives: the compressed motion frames from the previous chunk (history), noise to be denoised (the new frames), and a reference image. These are concatenated with appropriate masking so the model knows which parts are conditioning input and which parts it needs to generate.
Why This Approach Is Different (the deeper insight)
Here's the conventional way previous systems worked. You train a high-quality "teacher" model that can look at all frames freely — past, present, future. Then you create a faster "student" model that can only look backward. The student learns from the teacher, but it has to learn the teacher's behavior while also adapting to a completely different way of seeing the video.
Imagine learning to paint by studying a master painter's work — but the master can see the entire canvas while you're forced to look through a keyhole that only shows the left side. Even if you learn the same techniques, you'll miss things.
SoulX-FlashTalk keeps both teacher and student working the same way — both can see all the frames within their chunk. The student just needs to learn to do the same thing faster (fewer denoising steps), not learn a different way of seeing.
This also means training is dramatically faster. SoulX-FlashTalk's distillation takes around 1,200 steps total. A comparable prior system, LiveAvatar, needed 27,500 steps. That's roughly a 23× reduction in training cost.
Training: Two Stages, Each Solving a Different Problem
Stage 1 — Teaching the model to work within constraints. The full teacher model was trained to generate high-quality video at full resolution and length. But real-time inference requires lower resolution and shorter clips. Stage 1 adapts the model to maintain quality under these constraints. You're not changing the model — you're teaching it to do great work within a smaller canvas.
Stage 2 — Making generation fast and self-correcting. The full diffusion process requires many denoising steps. Real-time inference needs it done in one or two. This stage distills the multi-step process into a fast single-step generator.
But the crucial addition is self-correction. Remember the error accumulation problem — each chunk conditions on the previous chunk's output, and small errors compound. SoulX-FlashTalk addresses this during training: the model generates several chunks in a row, then evaluates how much the generated chunks have drifted from the real video. It learns to anticipate and compensate for its own imperfections. This isn't a post-processing fix — it's baked into the model's weights during training.
Think of it like a musician rehearsing with a slightly out-of-tune recording of themselves, over and over, until they can play perfectly even when the reference isn't perfect.
For domain experts: this combines Distribution Matching Distillation (DMD) with a multi-step retrospective self-correction mechanism inspired by Self-Forcing++. The generator autoregressively synthesizes k chunks conditioned on past motion latents, while Real and Fake score networks align data distributions through distillation losses. Motion latent conditioning in DMD further stabilizes output quality under autoregressive generation.
The Inference Stack (why the engineering matters as much as the model)
A 14-billion-parameter model generating 32 frames per second with 0.87-second startup latency doesn't happen by accident. The model alone isn't enough — every component of the pipeline had to be engineered for speed. This is where I spent most of my time contributing, and it's where the gap between "research" and "something that actually works" becomes concrete.
The VAE bottleneck that nobody talks about: The compression/decompression step (the VAE) was a major latency contributor that's easy to overlook because it's not "the AI model." SoulX-FlashTalk parallelizes the VAE across GPUs using a slicing strategy, achieving roughly 5× speedup. Without this, the VAE alone would push the system past real-time — the smartest model in the world doesn't matter if the compression step can't keep up.
Running the model across 8 GPUs simultaneously: The DiT uses a combination of two parallelism strategies across 8 H800 GPUs. One strategy (Ulysses) splits the attention computation by distributing different attention heads to different GPUs. The other (Ring Attention) splits the video sequence itself — different GPUs process different time segments. Together, this yields approximately 5× speedup on the model forward pass.
Hardware-specific optimization: The attention computation uses FlashAttention 3, specifically tuned for the Hopper architecture (the chip design inside H800 GPUs). This isn't a generic software speedup — it's adapting the computation to the specific way these particular chips move data through memory.
The 0.87-second startup and 32 FPS throughput are system-level results. No single optimization achieves them. If any one component — the VAE, the parallelism, the kernel optimization — was 2× slower than it is, the system falls below real-time. This kind of tight latency budget is what separates a research prototype from a working product.
What I Took Away From This
Three things stuck with me.
Question inherited constraints. The assumption that real-time streaming requires fully unidirectional attention was treated as given for years. It made intuitive sense — if you're streaming, you can only look backward, right? But "streaming" actually means chunk-by-chunk, and within a chunk, bidirectional attention is not only possible but better. The constraint was never actually required. It was an over-specification that cost quality for no benefit.
This pattern shows up everywhere in engineering: constraints that made sense once, then got baked in and stopped being questioned.
Inference engineering is the product. A trained model is a starting point, not a product. Getting a 14B model to 32 FPS involved VAE parallelism, hybrid attention sharding, hardware-specific kernel work, and careful pipeline orchestration. None of that is in the research paper. All of it is in the gap between "we trained a model" and "this actually works."
Video generation is its own discipline. It borrows transformer architectures from language models, but the problems it solves — spatial-temporal coherence, error accumulation, chunk-based streaming, 3D attention at massive scale — are fundamentally different from next-token prediction. If you understand LLMs and assume you understand video generation, you're going to be surprised by what's actually hard.
SoulX-FlashTalk is open-sourced at github.com/Soul-AILab/SoulX-FlashTalk. The technical report is on arXiv (2512.23379). The model weights are available on Hugging Face.